Sheepdog 概述
分布式存储简介
分布式存储系统指的是大量普通PC服务器通过网络互联,作为一个整体对外提供存储服务的系统。分布式存储系统按提供的存储接口来说可以分为三种:对象存储系统,类似于键值存储的数据库,只对客户端提供了基于主键的CRUD,即增、删、改、查的操作;块存储系统,即能够给客户端动态地提供硬盘等块设备资源;文件存储系统,与传统的文件系统如Ext4等类似,实现了对目录、文件属性等特性的支持。当下十分流行的云存储服务,就是利用计算机集群,依靠分布式存储系统对外提供存储服务的一种云计算应用。
Sheepdog项目介绍
Sheepdog是一个开源的分布式存储系统,主要用于为QEMU 块设备驱动(block driver)提供如硬盘等虚拟块设备。该项目最初在2009年由日本NTT实验室创建,在近几年随着云存储的升温得到了迅速的发展。相比于GFS,Ceph等其他分布式存储系统,它最大的特点在于采用的是完全对称的结构,没有一个节点单独提供元数据服务,也就避免了出现单点故障的情况。在架构上,Sheepdog主要由集群管理器(Cluster Manager)、对象管理(Object Storage)两个模块组成。Sheepdog本身不提供集群管理功能,但能够利用zookper,corosync等集群管理工具对各个节点进行操作。在数据存储上,QEMU块设备驱动将虚拟硬盘镜像(Virtual Disk Image, VDI)分割为许多个对象(Object)文件,由Sheepdog负责管理这些对象文件,并利用数据冗余实现高可用性。每个节点运行的守护进程sheep负责对本节点存储的对象进行管理。
Sheepdog基本架构
Sheepdog整体架构
Sheepdog的结构是完全对称的,没有类似元数据服务的中心节点。下图是Sheepdog的架构: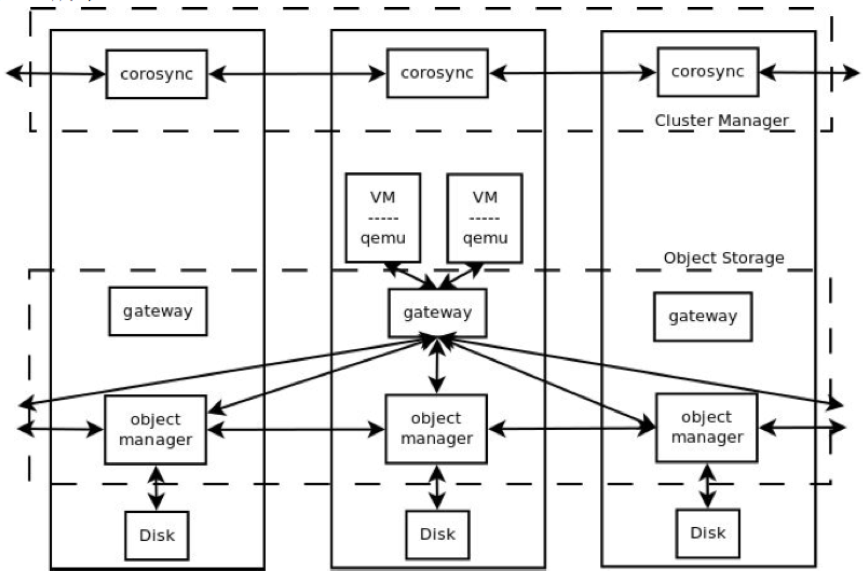
Sheepdog主要由集群管理器和对象存储两部分组成。集群管理器模块用于管理成员(包括节点的添加、删除等),以及一些需要所有节点统一执行的操作(如创建VDI,VDI快照等),主要使用诸如zookeeper,corosync等工具实现。
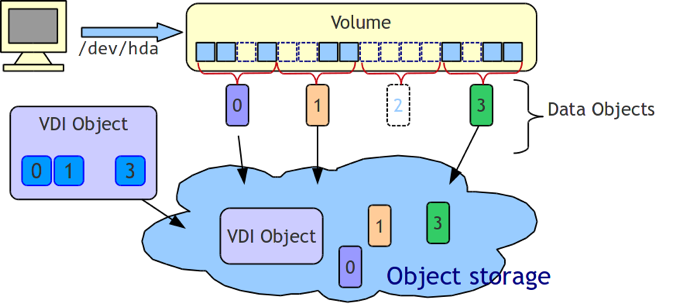
在对象存储中,Sheepdog需要利用集群创建并维护一个分布式对象存储系统,用于存储管理四种类型的对象,每种类型的对象保存特定意义的数据。对象存储功能由对象管理器(Object Manager)和路由(Gateway)两个模块实现。QEMU块设备驱动将虚拟硬盘映像分为许多个固定大小(默认4M)的对象后,通过同一个上的节点的路由存储到本地对象中。举个例子,当某个节点中运行的一台虚拟机需要读写虚拟硬盘时,节点中的路由会从该节点上运行的QEMU块设备驱动接收IO请求(包含对象ID,偏移量,长度,操作类型等数据),根据一致性哈希算法计算对象所在的节点并把请求转发到对应节点中,对应节点上的对象管理器再把接收到的IO请求在本地磁盘上解析执行。这些工作均由运行在各节点上的sheepdog守护进程(sheep)完成。
sheepdog元数据管理模型
元数据,简单讲即数据的数据,是描述某种类型资源的属性、并对这种资源进行定位和管理、同时有助于数据检索的数据。目前,分布式系统中的元数据管理主要包括集中式元数据服务模型,分布式元数据服务模型和无元数据服务模型等模型。
集中式元数据服务模型,通常提供一个中央元数据服务器负责元数据的存储和客户端查询请求,它提供统一的文件系统命名空间,并处理名字解析和数据定位等访问控制功能。它最大优点就是设计实现简单,本质上相当于设计一个单机应用程序,对外提供网络访问接口即可,缺点是性能瓶颈和单点故障问题。大多数分布式文件系统采用了集中式的元数据服务,如Lustre, PVFS, StorNext, GFS等。
分布式元数据服务模型使用多台服务器构成集群协同为分布式文件系统提供元数据服务,从而消除集中式元数据服务模型的性能瓶颈和单点故障问题。这种模型可以细分为两类,一为全对等模式,即集群中的每个元数据服务器是完全对等的,每个都可以独立对外提供元数据服务,然后集群内部进行元数据同步,保持数据一致性,比如ISILON、LoongStore、CZSS等。另一类为全分布模式,集群中的每个元数据服务器负责部分元数据服务(分区可以重叠),共同构成完整的元数据服务,比如PanFS, GPFS, Ceph等。分布式元数据模型解决了集中式模型的问题,却产生了新的问题,即性能开销和数据一致性问题。
既然集中式或分布式元数据服务模型都不能彻底地解决问题,那么直接去掉元数据服务器,是否就可以避免这些问题呢?理论上,无元数据服务模型是完全可行的,寻找到元数据查询定位的替代方法即可。理想情况下,这种模型消除了元数据的性能瓶颈、单点故障等一系列相关问题,系统扩展性显著提高,系统并发性和性能将实现线性扩展增长。对于海量小文件应用,这种设计能够有效解决元数据的难点问题。它的负面影响是,数据一致问题更加复杂,文件目录遍历操作效率低下,缺乏全局监控管理功能。同时也导致客户端承担了更多的职能,比如文件定位、名字空间缓存、逻辑卷视图维护等等,这些都增加了客户端的负载,占用相当的CPU和内存。
Sheepdog集群管理
Sheepdog集群管理
Sheepdog 采用其他的集群管理工具来实现对各个节点的管理。它支持的后端集群管理工具有很多种,包括了local driver, corosync, Zookeeper 和Accord。Corosync是sheepdog默认的集群管理工具,但由于它是为小规模集群设计的,只能可靠地运行在少于15个节点的集群中;Zookeeper是一个针对大型集群且可靠的分布式协调系统,提供的功能包括配置维护、名字服务、分布式同步、分组服务等;Accord主要是针对写密集型的集群来设计的。
集群更新策略
利用zookeeper等集群管理工具,sheepdog可动态调整集群大小。当集群中节点的成员发生变化 (如一个新节点加入或者某些节点离开)时,sheepdog会启动对应的恢复机制,重新分配节点数据。手动更新集群时需要手动关闭自动恢复机制,断开节点,升级完节点后再把节点加入集群,这样可减少数据重新分配。
在更新节点上正在的运行程序时,有两种情况存在。一种是允许整个集群暂时关闭,一种是不允许集群全部关闭。若允许集群暂时关闭不进行服务,则情况较为简单,只需将各个节点更新再重启集群即可。但在实际应用中通常是不允许集群全部关闭的。由于sheepdog所存储的对象在多个节点上有多个备份,可以先关闭要更新的一个节点,Sheepdog会将节点上的数据自动重新进行数据分配,且保证了服务不会中断。在更新完该节点后,重新将节点加入集群,这时候sheepdog可以发现该节点中存储的某些数据比其他节点中相同的数据要旧,会启动sheepdog数据恢复机制,将其他节点上的更新过的数据同步到该节点中。当集群中所有节点的状态一致时,再进行下一个节点的更新。
对象节点映射关系
Sheepdog的每个节点都保存一个本地的节点数组,数组保存了节点的IP地址信息。这样通过节点ID查找节点位置,只是一个数组的下标解引操作,之后sheepdog通过TCP的方式以点对点的形式来传递数据。Sheepdog中,使用了一致性哈希算法来确定存储对象的具体存储节点。哈希函数使用了离散度较好的FNV-1a 哈希函数。
一致性哈希算法
一致性哈希算法最早在1997年由D. Karger等人提出,用于改善分布式网页服务器的平衡性,解决单点访问量过大的问题。分布式的网页服务器的机器数量是不固定的,在一个活跃的集群中可以进行节点的新增和删除。如果用一般的哈希函数,如线性同余函数 ,将对象映射到桶中,那么当桶的数目增加或减少时,整个哈希表都需要重新计算,存储在集群中的大部分对象将重新分布,也就是说,导致了不一致性。而一致性哈希算法可以有效地解决这个问题。
一致性哈希算法的原理是这样的:首先选择一个标准的哈希函数(例如MD5),假设映射到的哈希空间有个桶,将每个桶按顺序首尾相连形成一个圆环,如图XXX所示。分别计算节点和存储对象的哈希值,然后将存储对象放入顺时针方向上距离它最近的节点中。删除或添加节点后,对象的存放仍然要符合上述规则,这样就保证了只有少量的存储对象需要移动。在实际的工程中,为了使存储对象在节点上的分布更加均匀,可以将一个节点在哈希空间中复制到几个随机的点。
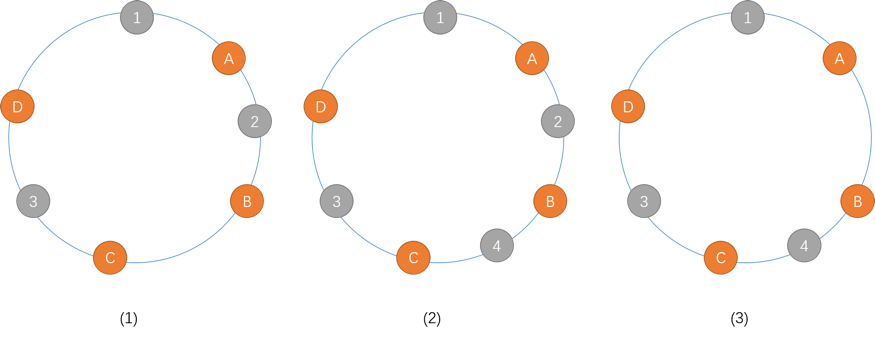
(1)节点1,2,3,4和对象A,B,C,D分别映射到圆环上,节点1存放对象D,2存放A,3存放B和C。
(2)增加节点4后,B会移动到节点4,其他对象保持不变。
(3)删去节点2后,A移动到节点4,其他对象保持不变。
一致性哈希有如下特性 :
- 单调(Monotonicity):新增节点时,旧的对象或者映射到新增加的节点上或者位置不变,但是不会映射到旧的节点
- 平衡(Balance):对象映射到每个桶的概率基本是相等的
- 分散性(Spread)低:一个对象映射到较少的节点上
Sheepdog存储管理
存储对象管理
在QEMU的虚拟化中,虚拟硬盘被切分为 4M 大小的对象,对象稀疏存储地存储在各个节点中。每个存储对象由全局唯一的64位整数标识,并复制到多个节点中。QEMU块设备驱动程序不关心在哪里存储对象,而是由Sheepdog的对象存储系统来负责定位和管理本地文件系统中存放的对象。sheepdog的默认行为是为每个对象创建3个副本(可以设置成2~4个),保证了高用性。存储的所有对象都还有一个扩展属性(sheepdog.copies),表示该对象的副本数目。
对象类型
Sheepdog的存储对象有四种类型:
- 数据对象:包含了实际的虚拟磁盘映像(VDI)数据,虚拟磁盘VDI被分割为固定大小的数据对象,sheepdog客户端主要访问这些对象。
- vdi 对象:包含了虚拟磁盘映像的元数据(例如映像名称、磁盘大小、创建时间、数据对象的ID等)
- 虚拟机对象:存储运行虚拟机时的虚拟机状态,在创建快照时会用到。
- vdi 属性对象:存储VDI的一些属性,属性是键值样式,类似于常规文件的扩展属性。
对象ID规则
- 0 – 31(32bits):不同类型含义不同
- 32 - 55(24bits):VDI id
- 56 - 59(4bits):保留
- 60 - 63(4bits):对象类型标识符
每个VDI有一个全局唯一ID(VDI id),可以通过对VDI名字进行hash计算获得,存储对象的低32位的含义如下:
| 对象类型 | 低32位的含义 |
|---|---|
| 数据对象 | 虚拟磁盘映像中的索引号 |
| vdi 对象 | 不使用,都是0 |
| 虚拟机对象 | 虚拟机映像中的索引号 |
| vdi 属性对象 | 属性键值的哈希值 |
对象IO操作
在写过程中,路由使用一致性哈希算法计算目标节点,之后向存储节点建立 TCP 连接,向所有目标节点发送写入请求。当所有副本都可以成功更新时,写入请求成功。这样可以避免发生由于复制对象未被完全更新,路由从未被更新的对象读取旧数据的情况。
对于读过程,路由使用一致性哈希算法计算目标节点,并向其中一个目标节点发送读取请求。
在对象复制过程中,如果在转发写入I / O请求期间节点崩溃,则复制的一致性可能会中断,因此路由在首次读取对象时会尝试修复一致性,即从一个目标节点中读取整个对象的数据,并用其覆盖所有节点上的副本。
对象恢复
Sheepdog将每个历史版本(epoch)的所有节点成员身份的历史记录保存在每个节点上的特定文件夹中。每个文件都保存了该时刻的所有节点的信息(包括IP地址,端口号,虚拟节点的数量等)。

利用这些信息,当某个节点中 的数据与其他节点上的副本不一致时,sheepdog可以按照以下操作进行对象恢复:
- 从所有节点接收所有已存储的对象ID
- 通过一致性哈希计算本节点上要保存的所有对象
- 创建对象ID的列表文件
- 发送读取请求以获取其ID在列表文件中的对象。 请求被发送到上一时刻拥有该对象的节点。
- 将对象存储到当前epoch目录
如果某一时刻QEMU块设备驱动需要对尚未恢复的对象发送IO请求,Sheepdog会阻止请求并优先进行对象恢复。
日志
当守护进程sheep在写操作过程期间失败时,对象可能被部分更新,对于虚拟机来说,这不是个问题,因为虚拟机没有收到成功信号,不能保证写入扇区的内容。但是如果vdi对象被部分更新,VDI元数据可能被部分损坏。为了避免这个问题,sheepdog使用日志对vdi对象进行写操作,过程如下:
- 创建日志文件
- 首先将数据写入日志文件
- 将数据写入vdi对象
- 删除日志文件
数据冗余
在分布式存储系统中通常会使用数据冗余来提高系统的可靠性。数据冗余机制主要有副本和纠删码(Erasure Coding)等。副本虽然可靠程度高,但是存储利用率非常低。纠删码能显著提高存储利用率,在分布式存储系统中应用广泛。
纠删码中的Maximum Distance Separable(MDS)编码能使存储利用率达到最优。基于范德蒙德矩阵的Reed Solomon Code是一种典型的MDS编码,其基本思想是将范德蒙德矩阵$A$作为生成矩阵,与原始的数据向量$X$相乘,得到校验数据向量$C$,假设$X$和$C$的维度分别是$n$和$m(n<m)$。编码的算法如下:
$$\begin{bmatrix} 1 & 1 & ... & 1 \\ 1 & 2 & ... & n \\ 1 & 4 & ... & n^2 \\ ... & ... & ... & ... \\ 1 & 2^{m-1} & ... & n^{m-1} \\ \end{bmatrix} * \begin{bmatrix} X_1 \\ X_2 \\ X_3 \\ ... \\ X_n \\ \end{bmatrix} = \begin{bmatrix} C_1 \\ C_2 \\ C_3 \\ ... \\ C_n \\ \end{bmatrix}$$记 $n * n$ 维单位矩阵为$E$,则编码公式也可以写成:
$$\begin{bmatrix} E \\ A \\ \end{bmatrix} * X = \begin{bmatrix} X \\ C \\ \end{bmatrix}$$如果一部分数据传送出错或者丢失,则可以用纠错算法恢复数据。纠错算法最多能容忍$m$个错误,从上式左右两边剔除错误的行,在剩下的行中任意选$n$行,得到$BX = Y$ ,两边同乘以$B^{-1}$得$X = B^{-1}Y$,从而恢复原始数据。
Reed Solomon算法改善了存储空间的利用率,但是由于编码解码代价较高,所以导致高延迟和低吞吐率。另外一种纠删码Regenerating Codes则可以提高数据恢复的带宽。
对象缓存机制
Sheepdog集群中的每个节点都依赖于本地文件系统来存储对象(如VDI对象,数据对象等)。在各个运行sheep守护进程的节点上,对象缓存会为该节点上的所有数据对象和VDI对象建立缓存。这一层建立在本地文件系统之上的缓存,能够把运行在本节点上的客户端(虚拟机)发送到路由(gateway)的请求解析为本地请求,而不是通过网络IO让路由把请求发送到其他节点中,大大地简化了网络负担同时提高了IO效率。
QEMU中提供的块设备虚拟化,简单地以本地文件作为后端存储。在宿主机上,使用宿主机的内存页来缓存虚拟硬盘的block。在内核内部这些块被映射到宿主机内存的page中并因此能依赖内核的内存管理机制将这些page上的数据写回(同步)到文件中;当虚拟机读写某个block时,内核也将按需在内存中分配page来满足对这些block的读写请求。这种读写机制可以用下图来表示:
Sheepdog的对象缓存机制也与QEMU的类似,主要的区别在于虚拟硬盘的block不是被映射到内存page上而是映射到固定大小的磁盘文件(对象)中,而这些文件可能有多个副本存储在其他节点中。在使用Object cache的情况下,对于一台虚拟机的写请求,本节点的sheep守护进程就会扮演类似于内核的角色,将写请求更新到本节点存储的对象上并记录被更新的dirty对象,之后再将更新同步到其他节点上该对象的副本中。
但由于该模块的测试时不稳定,在0.9.0以后的版本中已经被弃用了。
Sheepdog优劣势分析
优势
- 无需考虑元数据中心节点的性能,不会发生单点失败。这样的架构避免了在中心节点上低效地串行执行任务,也无需考虑中心节点宕机时带来的效率损失。此外,sheepdog也提供了修复机制使得多个节点出现问题时也能够方便地处理。
- 架构简单易懂,便于配置、使用及维护。Sheepdog专注于提供块设备的虚拟,相比于其他分布式存储项目其架构比较清晰易懂,能让使用者快速学习上手。此外,在配置了多个硬盘的节点中,也无需手动配置RAID软件或使用另外的RAID控制器,Sheepdog能够自动以RAID0的方式管理该节点上的多个硬盘。
- 资源使用率较高。每个节点同时作为宿主机和存储服务器工作,提高了节点中CPU和IO的利用率。
劣势
- 仅仅为QEMU提供块存储接口。与其他实现了多种存储接口的分布式存储系统如Ceph,GlusterFS相比,sheepdog只实现了QEMU块驱动的接口,因此只能为虚拟机提供块设备,再依赖于虚拟机上的文件系统为虚拟机提供存储访问。
- 部分功能还不够成熟稳定。从项目开发状态文档的表格中可以发现,诸如Object Cache、Erasure Code等功能模块的实现还存在若干问题,在该项目的Github上我们还发现Object Cache曾被包含在Release版本中,而在后来的版本中又被删除了。因此目前多数开发者更倾向于使用Ceph等较为成熟的系统作为虚拟机的底层存储。
参考文献
[1] 杨传辉. 大规模分布式存储系统: 原理解析与架构实战[J].
[2] 刘爱贵.分布式文件系统元数据服务模型[EB/0L]. [2011.09.05].
[3] 刘恋,郑彪,龚奕利.分布式文件系统中元数据操作的优化: 计算机应用[J],2012,32(12):3271 3273.
[4] Dimakis, A., Godfrey, P., Wu, Y., Wainwright, M. & Ramchandran, K. Network Coding for Distributed Storage Systems. arXiv (2008).
[5] Li J. & Li B. Erasure coding for cloud storage systems: A survey. International Conference on Tsingua Science and Technology vol. 18 no. 3, 259-272 (2013)
[6] Reed, I. & Solomon G. Polynomial codes over certain finite field. J Soc. Indust. Al. Math vol. 8 no. 2, 300-304 (1960).
[7] Karger, D. et al. Web caching with consistent hashing. Comput Netw 31, 1203–1213 (1999).