原文: Zab: High-performance broadcast for primary-backup systems
简介
Zookeeper是一个多节点的分布式服务,在大多数节点(quorum)不宕机的情况下就能够正常工作。
Zookeeper使用主-从架构来维护各副本的状态一致性。在Zookeeper中,主节点负责接收、执行所有客户端发来的请求,并通过Zab(Zookeeper Atomic Broadcast)协议,将状态的变更以事务(Transaction)的形式发送到各个备节点中。
当主节点宕机时,在继续处理新的请求前,所有节点会执行一个恢复协议,对当前的集群状态达成一致,并选举出一个新的主节点。只有获得大多数节点的投票,一个节点才能成为主节点。由于节点有可能会宕机并恢复,因此集群中的主节点可能会发生变化,一个节点也可能多次成为主节点。为了区分不同时期的主节点,我们赋予每个被选出的主节点一个实例号(instance value)。一个给定的实例号最多只能对应到一个节点。
Zab设计的一个关键点在于,状态的变化是以相对于前一个状态的增量形式发送的,也就是说这里隐式地依赖了状态变化的顺序。因此,状态的增量变化无法被乱序接受,并且保证主节点上发生的一次状态变更之前的所有状态变更(prefix of the stage changes)均已被执行到集群中的其他节点是至关重要的。状态变更是幂等的,因此只要执行顺序和发送顺序相同,多次执行同一次状态变更就不会发生不一致。因此,这样就足够保证执行“至少一次”(at-least once)的语义,并且简化了实现。
我们的Zookeeper应用场景需要满足以下特性:
并发事务(Multiple outstanding transactions): 我们允许Zookeeper客户端同时提交多个操作,并保证以FIFO的顺序处理这些操作。然而,如Paxos等传统的实现复制状态机的协议并不直接支持这种特性:当多个Proposer各自发起事务时,Learner获知这些事务的顺序并不保证是一致的。
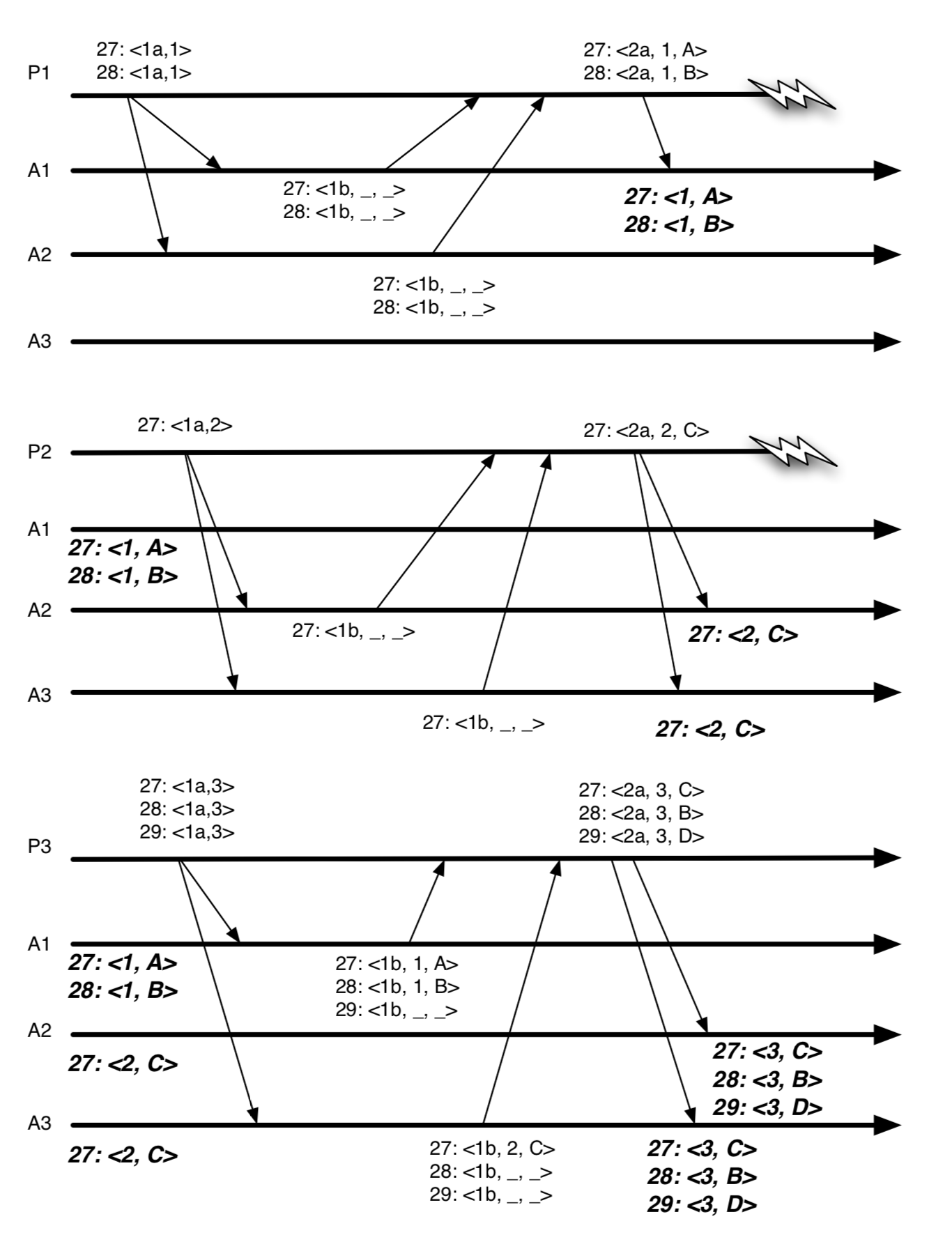
图1: Paxos的一轮执行过程
图1展示了我们的应用场景在Paxos中出现的一个问题。Proposer P1执行了Phase 1,序列号是27和28.
高效恢复(Efficient recovery)