Consumer源码解析
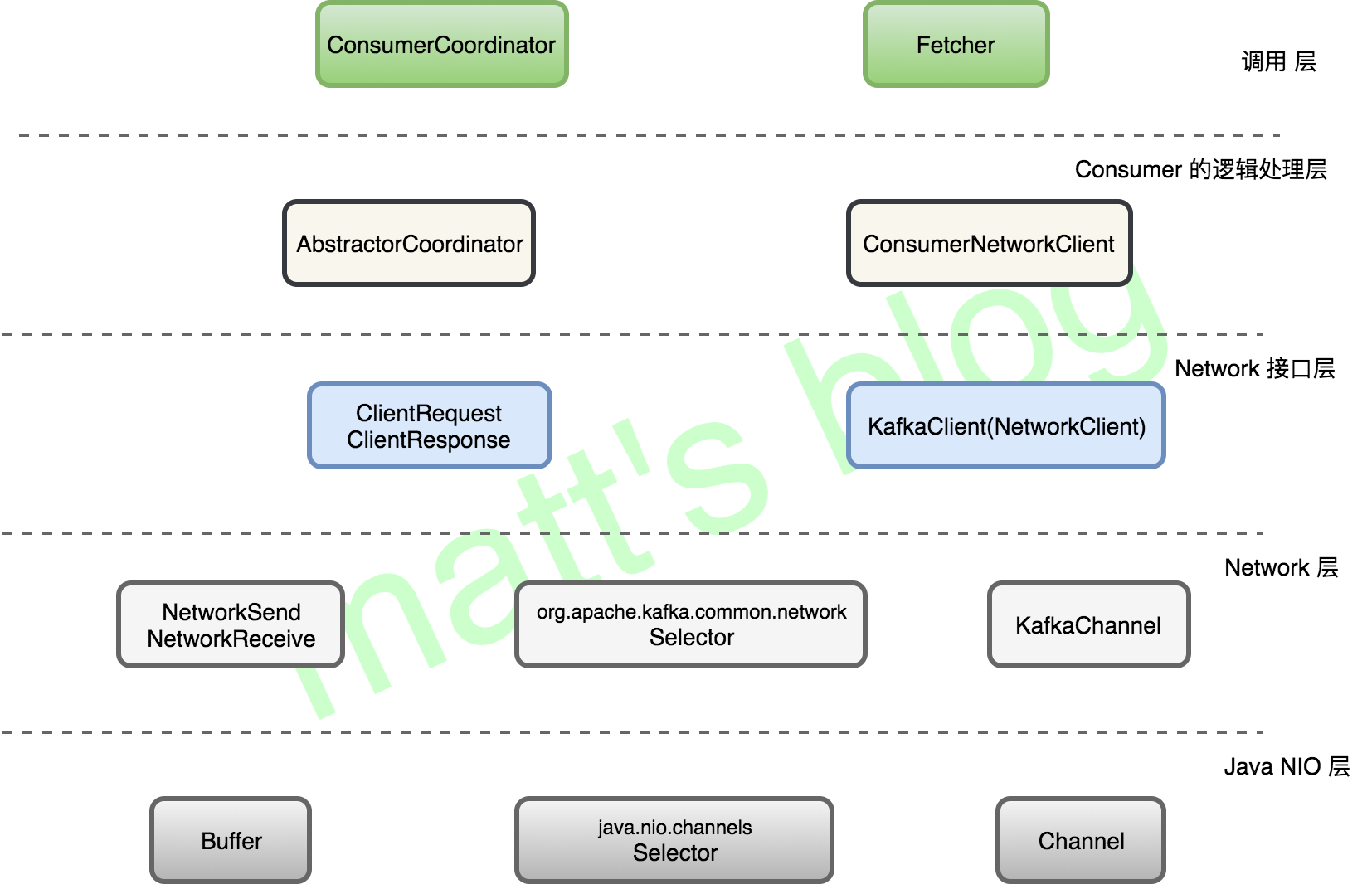
Consumer网络模型
consumer poll解析
Consumer poll 方法的真正实现是在 pollOnce() 方法中,这里直接看下其源码:
def _poll_once(self, timeout_ms, max_records):
"""Do one round of polling. In addition to checking for new data, this does
any needed heart-beating, auto-commits, and offset updates.
Arguments:
timeout_ms (int): The maximum time in milliseconds to block.
Returns:
dict: Map of topic to list of records (may be empty).
"""
# step1 获取GroupCoordinator并连接、加入、Sync Group,期间Group会进行rebalance并获取其订阅的的partition
self._coordinator.poll()
# Fetch positions if we have partitions we're subscribed to that we
# don't know the offset for
# step2 (如果某个partition的offset不合法的话)更新要拉取的各个partition的offset
if not self._subscription.has_all_fetch_positions():
self._update_fetch_positions(self._subscription.missing_fetch_positions())
# If data is available already, e.g. from a previous network client
# poll() call to commit, then just return it immediately
# step3 获取fetcher已经拉取到(fetched)的记录
records, partial = self._fetcher.fetched_records(max_records) # partial: fetchResponse返回的部分记录
if records:
# Before returning the fetched records, we can send off the
# next round of fetches and avoid block waiting for their
# responses to enable pipelining while the user is handling the
# fetched records.
if not partial: # 如果这次已经取出了fetchResponse中的所有记录,则先发下一个fetchRequest再返回
self._fetcher.send_fetches()
return records
# Send any new fetches (won't resend pending fetches)
# step4:到这里说明上次fetch到的记录已经全部返回了,需要再次向订阅的所有partition发送fetch请求,从多个partition拉取新的记录
# 注:只是将请求加入请求队列,并未实际发送
self._fetcher.send_fetches()
timeout_ms = min(timeout_ms, self._coordinator.time_to_next_poll() * 1000)
# step5 调用client的poll方法发送请求队列中的请求和接收回包
self._client.poll(timeout_ms=timeout_ms)
# after the long poll, we should check whether the group needs to rebalance
# prior to returning data so that the group can stabilize faster
# step6 如果group需要rebalance,直接返回空数据,以便更快地让group进入稳定状态(MemberState.STABLE)
if self._coordinator.need_rejoin():
return {}
records, _ = self._fetcher.fetched_records(max_records)
return records
在这里,我们把一个 pollOnce 模型分为6个部分,这里简单介绍一下:
- 连接 GroupCoordinator,并发送 join-group、sync-group 请求,加入 group 成功,并获取其分配的 tp 列表;
- 更新这些分配的 tp 列表的 the last committed offset(没有的话,根据其设置进行获取 offset);
- 调用 Fetcher 获取拉取的数据,如果有数据,立马返回,没有的话就进行下面的操作;
- 调用 Fetcher 发送 fetch 请求(只是加入队列,并未真正发送);
- 调用 poll() 方法发送请求;
- 如果 group 之前是需要 rebalacne 的,直接返回空集合,这样可以便于 group 尽快达到一个稳定的状态。
一个 Consumer 实例消费数据的前提是能够加入一个 group 成功,并获取其要订阅的 tp(topic-partition)列表,这都是在第一步中完成的,如果这个 group 是一个新的 group,那么 group 的状态将会由 Empty –> PreparingRebalance –> AwaitSync –> Stable 的变化过程,下面将会详细介绍。
Consumer join-group 过程
整体流程
Consumer Group状态变化流:
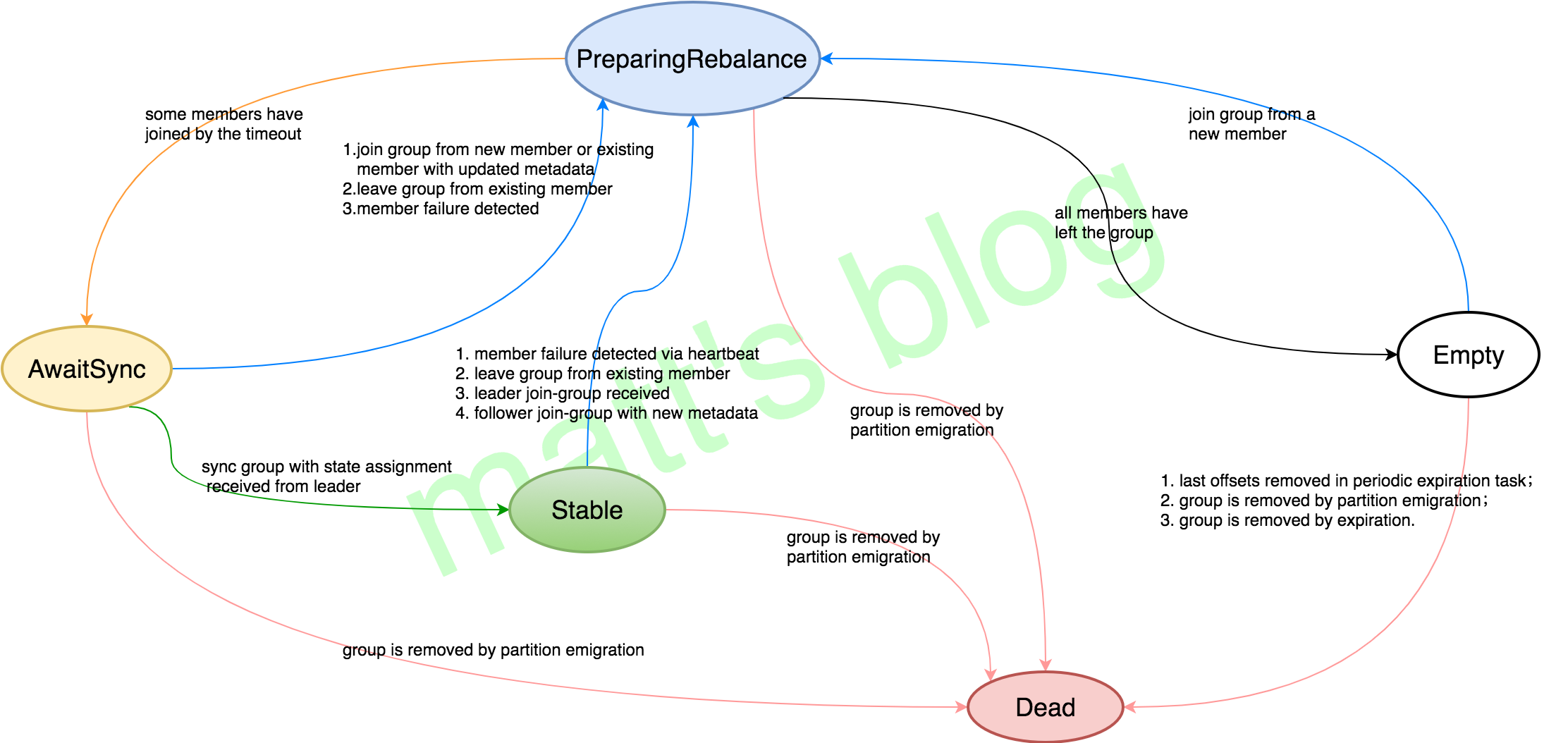
Group成员的状态定义
class MemberState(object):
UNJOINED = '<unjoined>' # the client is not part of a group
REBALANCING = '<rebalancing>' # the client has begun rebalancing
STABLE = '<stable>' # the client has joined and is sending heartbeats
ConsumerCoordinator.pool()
def poll(self):
"""
Poll for coordinator events. Only applicable if group_id is set, and
broker version supports GroupCoordinators. This ensures that the
coordinator is known, and if using automatic partition assignment,
ensures that the consumer has joined the group. This also handles
periodic offset commits if they are enabled.
本函数调用后可保证Coordinator是已知的,且在使用自动partition分配时保证consumer已经加入了这个group。
同时也用于进行周期性的offset提交(打开该特性时)
"""
if self.group_id is None or self.config['api_version'] < (0, 8, 2):
return
self._invoke_completed_offset_commit_callbacks()
# step1 获取GroupCoordinator地址,并建立连接
self.ensure_coordinator_ready()
if self.config['api_version'] >= (0, 9) and self._subscription.partitions_auto_assigned():
# step2 判断是否需要重新加入group(如果订阅的partitoni变化,或分配的partition变化??时需要rejoin)
if self.need_rejoin():
# due to a race condition between the initial metadata fetch and the
# initial rebalance, we need to ensure that the metadata is fresh
# before joining initially, and then request the metadata update. If
# metadata update arrives while the rebalance is still pending (for
# example, when the join group is still inflight), then we will lose
# track of the fact that we need to rebalance again to reflect the
# change to the topic subscription. Without ensuring that the
# metadata is fresh, any metadata update that changes the topic
# subscriptions and arrives while a rebalance is in progress will
# essentially be ignored. See KAFKA-3949 for the complete
# description of the problem.
if self._subscription.subscribed_pattern:
metadata_update = self._client.cluster.request_update()
self._client.poll(future=metadata_update)
# 确保group是active状态的;加入group;**并分配订阅的partition**
self.ensure_active_group()
# step3 检查心跳*线程*是否正常;如果心跳*线程*失败则抛出异常,否则更新poll的调用时间
self.poll_heartbeat()
# step4 设置了自动commit时,当定时到达时进行自动commit
self._maybe_auto_commit_offsets_async()
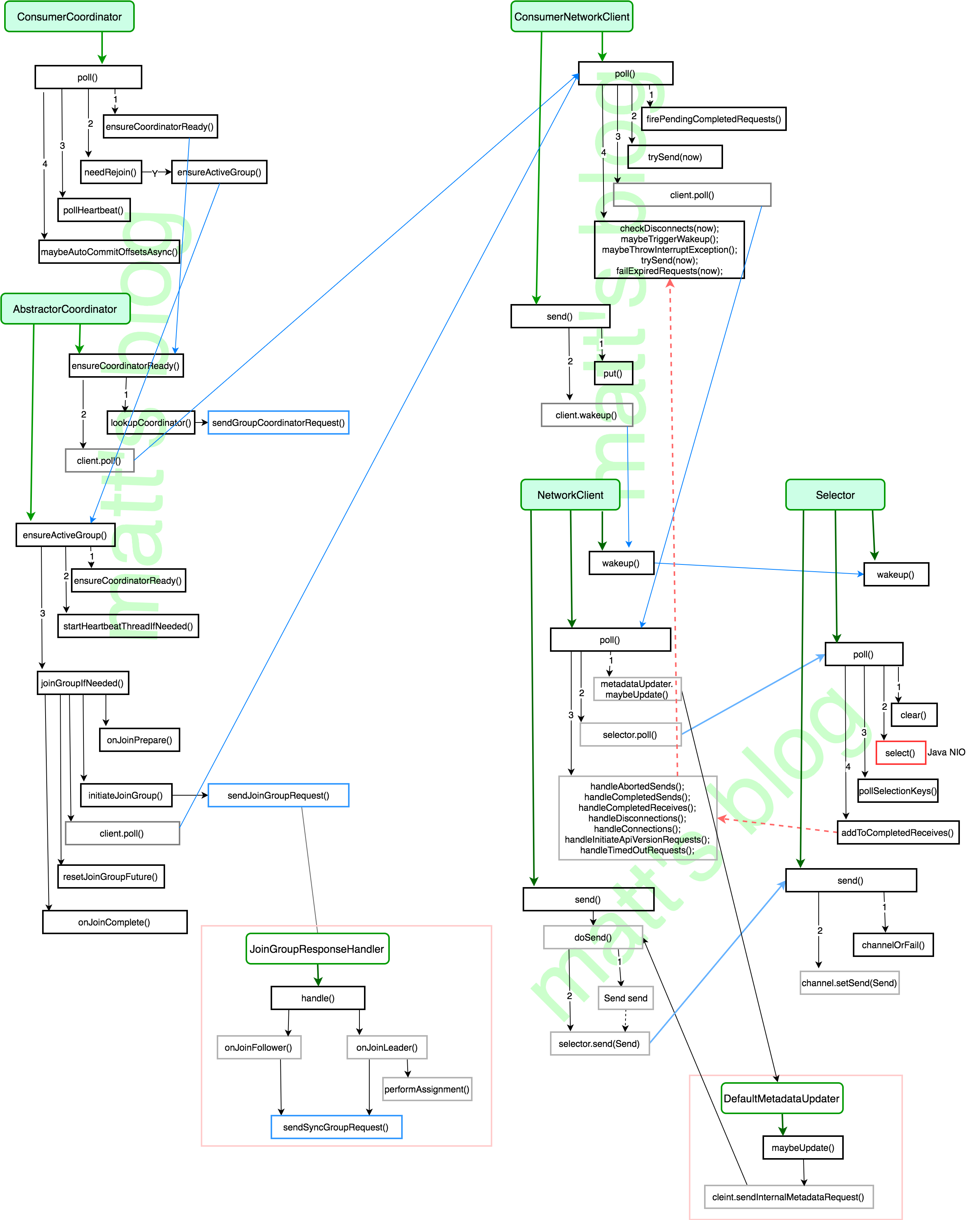
在 poll 方法中,具体实现,可以分为以下三步:
通过 subscribe() 方法订阅 topic, 并且 coordinator 未知,就初始化 Consumer Coordinator(在 ensureCoordinatorReady() 中实现,主要的作用是发送 GroupCoordinator 请求,并建立连接);
判断是否需要重新加入 group,如果订阅的 partition 变化或则分配的 partition 变化时,需要 rejoin,通过 ensureActiveGroup() 发送 join-group、sync-group 请求,加入 group 并获取其 assign 的 tp list;
检测心跳线程运行是否正常(需要定时向 GroupCoordinator 发送心跳线程,长时间未发送的话 group就会认为该实例已经挂了);
如果设置的是自动 commit,如果定时达到自动 commit。
这其中,有两个地方需要详细介绍,那就是第一步中的 ensureCoordinatorReady() 方法和第二步中的 ensureActiveGroup() 方法。
ConsumerCoordinator.ensure_coordinator_ready()
作用是选择一个负载(连接数)最小的broker,发送GroupCoordinator请求,并建立相应的TCP连接。
主要流程:
ensure_coordinator_ready() –> lookup_coordinator() –> _send_group_coordinator_request()。
ConsumerCoordinator.ensure_active_group()
作用是向已连接的GroupCoordinator发送 join-group、sync-grou请求,并获取分配的partition list
主要流程:
ensure_active_group() –> ensure_coordinator_ready() –> _start_heartbeat_thread() –> _send_join_group_request() -> _handle_join_success() -> _on_join_complete()
ConsumerCoordinator.on_join_complete()
作用:更新订阅的partition列表,更新对应的metadata,触发用户注册的listener。调用此函数时,一个consumer实例才算真正意义上加入了一个Consumer Group。
def _on_join_complete(self, generation, member_id, protocol,
member_assignment_bytes):
# only the leader is responsible for monitoring for metadata changes
# (i.e. partition changes)
if not self._is_leader:
self._assignment_snapshot = None
assignor = self._lookup_assignor(protocol)
assert assignor, 'Coordinator selected invalid assignment protocol: %s' % protocol
assignment = ConsumerProtocol.ASSIGNMENT.decode(member_assignment_bytes)
# set the flag to refresh last committed offsets
self._subscription.needs_fetch_committed_offsets = True
# update partition assignment
self._subscription.assign_from_subscribed(assignment.partitions())
# give the assignor a chance to update internal state
# based on the received assignment
assignor.on_assignment(assignment)
# reschedule the auto commit starting from now
self.next_auto_commit_deadline = time.time() + self.auto_commit_interval
assigned = set(self._subscription.assigned_partitions())
log.info("Setting newly assigned partitions %s for group %s",
assigned, self.group_id)
# execute the user's callback after rebalance
if self._subscription.listener:
try:
self._subscription.listener.on_partitions_assigned(assigned)
except Exception:
log.exception("User provided listener %s for group %s"
" failed on partition assignment: %s",
self._subscription.listener, self.group_id,
assigned)
Consumer poll模型综述
当一个 consumer 对象创建之后,只有 poll 方法调用时,consumer 才会真正去连接 kafka 集群,进行相关的操作,其 poll 方法具体实现如下:
def poll(self, timeout_ms=0, max_records=None):
"""Fetch data from assigned topics / partitions.
Records are fetched and returned in batches by topic-partition.
On each poll, consumer will try to use the last consumed offset as the
starting offset and fetch sequentially. The last consumed offset can be
manually set through :meth:`~kafka.KafkaConsumer.seek` or automatically
set as the last committed offset for the subscribed list of partitions.
Incompatible with iterator interface -- use one or the other, not both.
Arguments:
timeout_ms (int, optional): Milliseconds spent waiting in poll if
data is not available in the buffer. If 0, returns immediately
with any records that are available currently in the buffer,
else returns empty. Must not be negative. Default: 0
max_records (int, optional): The maximum number of records returned
in a single call to :meth:`~kafka.KafkaConsumer.poll`.
Default: Inherit value from max_poll_records.
Returns:
dict: Topic to list of records since the last fetch for the
subscribed list of topics and partitions.
"""
assert timeout_ms >= 0, 'Timeout must not be negative'
if max_records is None:
max_records = self.config['max_poll_records']
assert isinstance(max_records, int), 'max_records must be an integer'
assert max_records > 0, 'max_records must be positive'
# Poll for new data until the timeout expires
start = time.time()
remaining = timeout_ms
while True:
records = self._poll_once(remaining, max_records)
if records:
return records
elapsed_ms = (time.time() - start) * 1000
remaining = timeout_ms - elapsed_ms
if remaining <= 0:
return {}
如前所述,Consumer.poll()方法主要调用了_poll_once方法。
poll_once方法的主要流程如下:
- coordinator.poll():获取 GroupCoordinator 的地址,并建立相应 tcp 连接,发送 join-group、sync-group,之后才真正加入到了一个 group 中,并获取其要消费的 topic-partition 列表,如果设置了自动 commit,也会在这一步进行 commit,具体见上文。总之,对于一个新建的 group,group 状态将会从 Empty –> PreparingRebalance –> AwaiSync –> Stable;
- updateFetchPositions(): 在上一步中已经获取到了这个 consumer 实例要订阅的 topic-partition list,这一步更新其 fetch-position offset,以便进行拉取;
- fetcher.send_fetches():返回其 fetched records,并更新其 fetch-position offset,只有在 offset-commit 时(自动 commit 时,是在第一步实现的),才会更新其 committed offset;
- fetcher.send_fetches():只要订阅的 topic-partition list 没有未处理的 fetch 请求,就发送对这个 topic-partition 的 fetch 请求,在真正发送时,还是会按 node 级别去发送,leader 是同一个 node 的 topic-partition 会合成一个请求去发送;
- client.poll():调用底层 NetworkClient 提供的接口去发送相应的请求;
- coordinator.need_rejoin():如果当前实例分配的 topic-partition 列表发送了变化,那么这个 consumer group 就需要进行 rebalance。
poll_once的总体流程图如下:
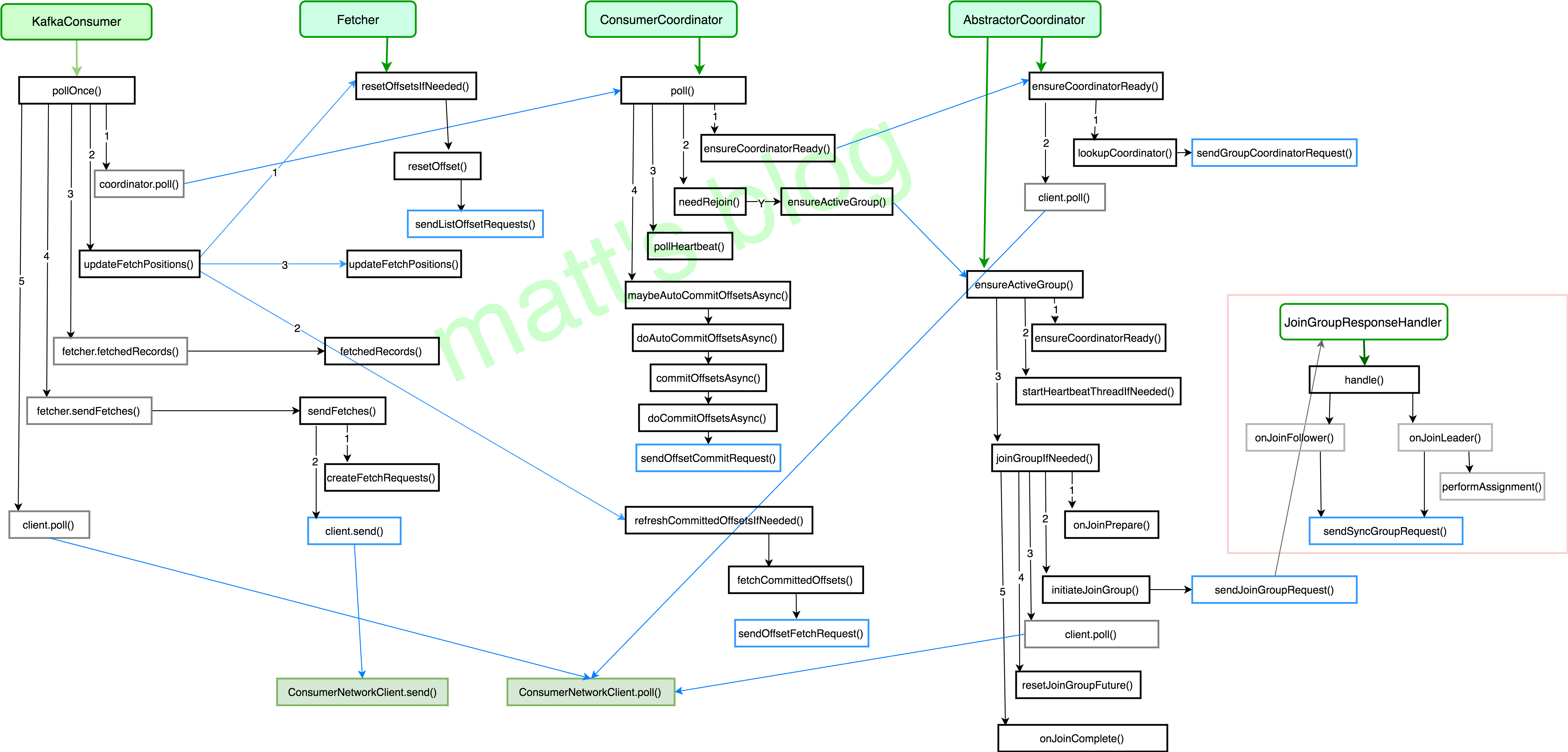
下面分别来看一下其中的几个主要函数:
coordinator.poll()
该函数在前文中已经详细分析过,一个 consumer 实例在这一步实现的内容是:
- 获取 GroupCoordinator 的地址,并建立相应 tcp 连接;
- 发送 join-group 请求,然后 group 将会进行 rebalance;
- 发送 sync-group 请求,之后才正在加入到了一个 group 中,这时会通过请求获取其要消费的 topic-partition 列表;
- 如果设置了自动 commit,也会在这一步进行 commit offset。
consumer.update_fetch_positions()
这个方法主要是用来更新这个 consumer 实例订阅的 topic-partition 列表的 fetch-offset 信息。在 Fetcher 中,这个 consumer 实例订阅的每个 topic-partition 都会有一个对应的 TopicPartitionState 对象,在这个对象中会记录以下这些内容:
class TopicPartitionState(object):
def __init__(self):
self.committed = None # last committed position
self.has_valid_position = False # whether we have valid position
self.paused = False # whether this partition has been paused by the user
self.awaiting_reset = False # whether we are awaiting reset
self.reset_strategy = None # the reset strategy if awaitingReset is set
self._position = None # offset exposed to the user
self.highwater = None
self.drop_pending_message_set = False
其中需要关注的几个属性是:
- position:Fetcher 下次去拉取时的 offset,Fecher 在拉取时需要知道这个值;
- committed:consumer 已经处理完的最新一条消息的 offset,consumer 主动调用 offset-commit 时会更新这个值;
- resetStrategy:这 topic-partition offset 重置的策略,重置之后,这个策略就会改为 null,防止再次操作。
update_fetch_positions() 这个方法的目的就是为了获取其订阅的每个 topic-partition 对应的 position,这样 Fetcher 才知道从哪个 offset 开始去拉取这个 topic-partition 的数据。
fetcher.send_fetches()
这个虽然是 pollOnce 的第四步,但我们这里放在第三步来讲,因为只有在发送 fetch 请求后,才能调用 fetcher.fetchedRecords() 获取到其拉取的数据,所以这里先介绍这个方法,其具体实现如下:
def send_fetches(self):
"""Send FetchRequests for all assigned partitions that do not already have
an in-flight fetch or pending fetch data.
Returns:
List of Futures: each future resolves to a FetchResponse
"""
futures = []
for node_id, request in six.iteritems(self._create_fetch_requests()):
if self._client.ready(node_id):
log.debug("Sending FetchRequest to node %s", node_id)
future = self._client.send(node_id, request)
future.add_callback(self._handle_fetch_response, request, time.time())
future.add_errback(log.error, 'Fetch to node %s failed: %s', node_id)
futures.append(future)
self._fetch_futures.extend(futures)
self._clean_done_fetch_futures()
return futures
在发送的 fetch 的过程中,总共分为以下两步:
- create_fetch_requests():为订阅的所有 topic-partition list 创建 fetch 请求(只要该topic-partition 没有还在处理的请求),创建的 fetch 请求依然是按照 node 级别创建的;
- client.send():发送 fetch 请求,并设置相应的 Listener,请求处理成功的话,就加入到 completedFetches 中,在加入这个 completedFetches 集合时,是按照 topic-partition 级别去加入,这样也就方便了后续的处理。
从这里可以看出,在每次发送 fetch 请求时,都会向所有可发送的 topic-partition 发送 fetch 请求,调用一次 fetcher.sendFetches,拉取到的数据,可需要多次 pollOnce 循环才能处理完,因为 Fetcher 线程是在后台运行,这也保证了尽可能少地阻塞用户的处理线程,因为如果 Fetcher 中没有可处理的数据,用户的线程是会阻塞在 poll 方法中的。
fetcher.fetched_records()
返回之前获取到的record,并更新offset
def fetched_records(self, max_records=None):
"""Returns previously fetched records and updates consumed offsets.
Arguments:
max_records (int): Maximum number of records returned. Defaults
to max_poll_records configuration.
Raises:
OffsetOutOfRangeError: if no subscription offset_reset_strategy
CorruptRecordException: if message crc validation fails (check_crcs
must be set to True)
RecordTooLargeError: if a message is larger than the currently
configured max_partition_fetch_bytes
TopicAuthorizationError: if consumer is not authorized to fetch
messages from the topic
Returns: (records (dict), partial (bool))
records: {TopicPartition: [messages]}
partial: True if records returned did not fully drain any pending
partition requests. This may be useful for choosing when to
pipeline additional fetch requests.
"""
if max_records is None:
max_records = self.config['max_poll_records']
assert max_records > 0
drained = collections.defaultdict(list)
records_remaining = max_records
while records_remaining > 0:
if not self._next_partition_records:
# 如果fetch未完成则退出循环
if not self._completed_fetches:
break
completion = self._completed_fetches.popleft()
self._next_partition_records = self._parse_fetched_data(completion)
else:
records_remaining -= self._append(drained,
self._next_partition_records,
records_remaining)
return dict(drained), bool(self._completed_fetches)
consumer 的 Fetcher 处理从 server 获取的 fetch response 大致分为以下几个过程:
- 通过
completed_fetches.popleft()获取已经成功的 fetch response(在 sendFetches() 方法中会把成功的结果放在这个集合中,是拆分为 topic-partition 的粒度放进去的); parse_fetched_data()处理上面获取的 completedFetch,构造成 PartitionRecords 类型;- 通过
append(drained, next_partition_records, records_remaining)方法处理 PartitionRecords 对象,在这个里面会去验证 fetchOffset 是否能对得上,只有 fetchOffset 是一致的情况下才会去处理相应的数据,并更新 the fetch offset 的信息,如果 fetchOffset 不一致,这里就不会处理,the fetch offset 就不会更新,下次 fetch 请求时是会接着 the fetch offset 的位置去请求相应的数据。 - 返回相应的 Records 数据。
consumer message generator
def _message_generator(self):
assert self.assignment() or self.subscription() is not None, 'No topic subscription or manual partition assignment'
while time.time() < self._consumer_timeout:
# 确保Coordinator是已知的,且在使用自动partition分配时保证consumer已经加入了这个group。
self._coordinator.poll()
# 对齐各个partition的offset
# Fetch offsets for any subscribed partitions that we arent tracking yet
if not self._subscription.has_all_fetch_positions():
partitions = self._subscription.missing_fetch_positions()
self._update_fetch_positions(partitions)
poll_ms = 1000 * (self._consumer_timeout - time.time())
if not self._fetcher.in_flight_fetches():
poll_ms = min(poll_ms, self.config['reconnect_backoff_ms'])
# 调用client的poll方法发送请求队列中的请求,并接收回包
self._client.poll(timeout_ms=poll_ms)
# after the long poll, we should check whether the group needs to rebalance
# prior to returning data so that the group can stabilize faster
# 先判断group是否需要rebalance再返回数据,以便更快地让group进入稳定状态(MemberState.STABLE)
if self._coordinator.need_rejoin():
continue
# We need to make sure we at least keep up with scheduled tasks,
# like heartbeats, auto-commits, and metadata refreshes
# 获取**下一次检查周期性任务的时间**(超时时间),如heart beat, auto commit和元数据更新是否按期执行
timeout_at = self._next_timeout()
# Because the consumer client poll does not sleep unless blocking on
# network IO, we need to explicitly sleep when we know we are idle
# because we haven't been assigned any partitions to fetch / consume
# 如果目前处于空闲状态(next timeout > now),则先sleep以免CPU空转
if self._use_consumer_group() and not self.assignment():
sleep_time = max(timeout_at - time.time(), 0)
if sleep_time > 0 and not self._client.in_flight_request_count():
time.sleep(sleep_time)
continue
# Short-circuit the fetch iterator if we are already timed out
# to avoid any unintentional interaction with fetcher setup
# 如果已经超时了(next timeout < now),则快速结束本次迭代器,防止与fetcher线程发生错误的交互
if time.time() > timeout_at:
continue
# 以上前置条件都检查通过,可以返回一条消息
for msg in self._fetcher:
yield msg
if time.time() > timeout_at:
log.debug("internal iterator timeout - breaking for poll")
break
if self._client.in_flight_request_count():
self._client.poll(timeout_ms=0)
# An else block on a for loop only executes if there was no break
# so this should only be called on a StopIteration from the fetcher
# We assume that it is safe to init_fetches when fetcher is done
# i.e., there are no more records stored internally
# 当fetcher中没有待取出的消息时才会走到此else分支,此时将fetch请求放入队列等待下次client.poll发送
else:
self._fetcher.send_fetches()
问题思考
为什么要让(Leader)Consumer自己分配Partition
https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Client-side+Assignment+Proposal
However, it relies on the server having access to the code implementing the assignment strategy, which is problematic for two reasons:
First is just a matter of convenience. New assignment strategies cannot be deployed to the server without updating configuration and restarting the cluster. It can be a significant operational undertaking just to provide the capability to do this.
Different assignment strategies have different validation requirements. For example, with a redundant partitioning scheme, a single partition can be assigned to multiple consumers. This limits the ability of the coordinator to validate assignments, which is one of the main reasons for having the coordinator do the assignment in the first place.
如果让Coordinator分配Partition,有两个问题:
- 这种情况下,如果要更新、添加Partition策略,就需要更新Server代码,代价太高,不方便。
- 不同的分配策略有不同的校验方式(例如在一个分区冗余分配的策略下,一个Partition可以被分给多个Consumer)。这就限制了Coordinator校验分配合法性的能力,这也是一开始让Coordinator执行分配的主要原因之一。